In July 2024, I worked on my Masters dissertation, ‘social media analysis of the cryptocurrency market.’ The project involved crawling Bitcoin price data from cryptocurrency data aggregators such as CoinMarketCap and CryptoCompare. This price data was correlated with the sentiment data from top social media sites including Twitter, Telegram, Reddit and BitcoinTalk.
The correlation between both datasets showed a relationship between the price of cryptocurrencies and social media sentiment. And most importantly, the level of impact each social media platform had on Bitcoin and altcoins. The best part about this project was when I built predictive model that can forecast the future price of the virtual assets.
Now, If you’ve got a similar project where you need the Bitcoin historical price data as a csv for download, I’ll show you the steps that enabled me get mine. I’ll also reveal some data cleaning steps such as the removal of stop words, institutional comments, and links. You’ll also get to know the machine learning technciques I used to model the data.
How to Gather Bitcoin Price Data
There are several cryptocurrency price aggregators that you can use to get cryptocrrency price dataset. Some of these platforms include:
- Cryptocompare
- Coinmarketcap
- Coingecko
Let’s take a look at one of these platforms:
Cryptocompare
For my dissertation, I used CryptoCompare to get Bitcoin price dataset for free. At the time, there was no need to use an API which made the data collection process straightforward. However, you’ll need to setup an API to crawl the data.
The dataset, on the other hand, was classified by year, month, and date, which made it easy to correlate with sentiments gotten around the same time. This means that I could check if comments made on social media within a given timeframe, did impact Bitcoin price. I could alslo develop a model that would take data for a given market season such as bull or bear season to predict price.
For instance, you’re trying to predict when the crypto alt season will begin in 2025. You can use historic data from Novemeber 2020 to forecast. The machine learning model you choose may need technical indicators such as relative strenghth index (RSI), moving average convergence divergence (MACD), stochastic, etc. to better predict the future price of these assets.
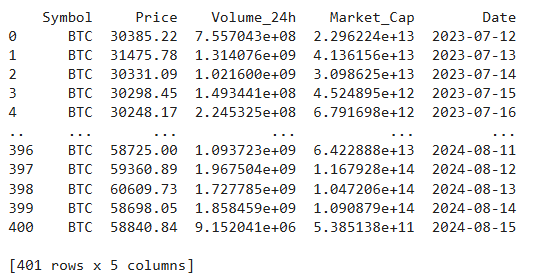
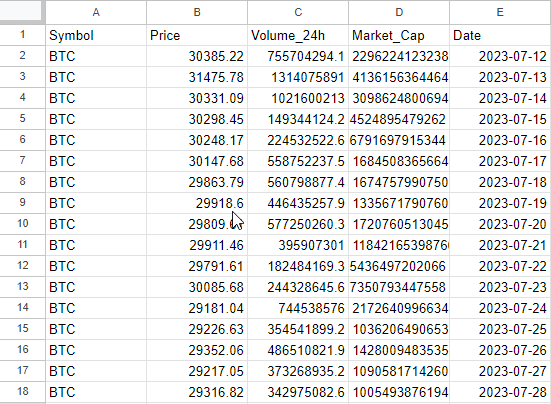
Apart from data as a feature as a feature in this dataset, other features were price, 24-hour volume, and market capitalization. The dataset is shown in Figure 1.
Code to Crawl Bitcoin Price Data from CryptoCompare
So let’s say you’ve chosen to use CryptoCompare, you’d need a code that can automatically crawl the data based on the date range you want. A code of this nature can help you begin:
import requests
import pandas as pd
from datetime import datetime
def fetch_crypto_data(symbol, limit=400, api_key='YOUR_API_KEY'):
"""
Fetch historical daily cryptocurrency data.
"""
url = 'https://min-api.cryptocompare.com/data/v2/histoday'
parameters = {
'fsym': symbol,
'tsym': 'USD',
'limit': limit,
'api_key': api_key
}
try:
response = requests.get(url, params=parameters)
response.raise_for_status() # Raise HTTPError for bad responses
data = response.json()
if data.get('Response') == 'Success':
return data['Data']['Data']
else:
print(f"Error fetching data for {symbol}: {data.get('Message', 'Unknown error')}")
return []
except requests.RequestException as e:
print(f"Request failed: {e}")
return []
# List of cryptocurrencies to fetch data for
crypto_symbols = ['BTC']
# Data storage
market_data = []
# Fetch and process data for each cryptocurrency
for symbol in crypto_symbols:
historical_data = fetch_crypto_data(symbol)
if historical_data:
for day_data in historical_data:
date = datetime.utcfromtimestamp(day_data['time']).strftime('%Y-%m-%d')
price = day_data['close']
volume_24h = day_data['volumeto']
# Market Cap omitted, as 'volumeto' is in USD
market_data.append({
'Symbol': symbol,
'Price': price,
'Volume_24h': volume_24h,
'Date': date
})
# Convert collected data to DataFrame
if market_data:
market_df = pd.DataFrame(market_data)
# Print and save the DataFrame
print(market_df.head())
market_df.to_csv('crypto_market_data.csv', index=False)
else:
print("No market data collected.")
The code above will crawl Bitcoin’s price data for the past 400 days. You can adjust this timeframe by changing the figure. Adjustments can also be made to the code to crawl other cryptocurrencies such as Ethereum, Ripple, Solana, Shiba, Dogecoin, etc.
Here’s a step by step process of setting up an account on the plaform to get an API that will work with the code:
Get the API key:
- Go https://min-api.cryptocompare.com/ to get an API.
- Register an account.
- Replace ‘YOUR_API_KEY’ in the code below wiht the key you got from platform.
- Run the code on Google Collab or any other Python compiler you’ve got.
import requests
import pandas as pd
from datetime import datetime
def fetch_crypto_data(symbol, limit=400, api_key=None):
url = 'https://min-api.cryptocompare.com/data/v2/histoday'
parameters = {
'fsym': symbol,
'tsym': 'USD',
'limit': limit,
'api_key': api_key
}
# Make the request to CryptoCompare
response = requests.get(url, params=parameters)
# Handle potential issues with the response
if response.status_code != 200:
print(f"Error fetching data for {symbol}: {response.status_code}")
return None
data = response.json()
if data.get('Response') != 'Success':
print(f"No data for {symbol}: {data.get('Message')}")
return None
return data
# List of cryptocurrencies to fetch
crypto_symbols = ['BTC']
api_key = 'YOUR_API_KEY' # Replace this with your actual API key
# Storage for market data
market_data = []
# Fetch data for each cryptocurrency
for symbol in crypto_symbols:
data = fetch_crypto_data(symbol, limit=400, api_key=api_key)
if data:
for day_data in data['Data']['Data']:
date = datetime.utcfromtimestamp(day_data['time']).strftime('%Y-%m-%d')
price = day_data['close']
volume_24h = day_data['volumeto']
market_cap = day_data['close'] * day_data['volumeto'] # Approximation
market_data.append({
'Symbol': symbol,
'Price': price,
'Volume_24h': volume_24h,
'Market_Cap': market_cap,
'Date': date
})
# Convert the collected data into a DataFrame
market_df = pd.DataFrame(market_data)
# Display the DataFrame or save it to a CSV file
print(market_df)
market_df.to_csv('crypto_market_data.csv', index=False)
How to Crawl Sentiment Data
There are so manny social media platforms that will help you build thousands of data instances for your project. Given their wide nature, you’d have to narrow down based on the audience type, age, and location. Consider the following platforms.
1. Twitter
Twitter’s data is updated every minute and second, hence, you can find real time sentiment data to pair with the price data. This real time data is ideal for predicting short term price movements. So let’s say you’re building a trading bot for scalpers, then you’d greatly rely on the data from Twitter.
2. Telegram
Telegram also has real time data from groups and channels. There has also been heightened interest on this media due to airdrops like Hamster Kombat, BLUM, Tapswap, Memfi, Dogs, and others. Telegram also has a younger demographic, hence, you may want to see what this class of users have to say. In line with that, there are more speculators than experienced traders on Telegram.
3. BitcoinTalk
BitcoinTalk has historic context with cryptocurreies. Bitcoin’s and Ethereum’s launch were first annouced on BitcoinTalk, and Satoshi Nakamoto, Bitcoin’s founder, is also the creator of the forum. You’d find trading analysis from experienced traders on BitcoinTalk. Thus, you can pair the sentiment of experienced traders with that of speculators to predict the next market direction.
Code to Crawl Social Media Data
The code below will enable you crawl the sentiment data from Telegram, Reddit and BitcoinTalk. You can adjust the code accordingly based on how many comments or sentiments you need from each platform.
You’ll also have to adjust the fields where API ID, Username and phone number are required. Telegram, for instance, will give you an API ID, associated with your phone number which you can use to crawl sentiments from the platform. BitcoinTalk, on the other hand, only requires a link to the web pages which will be given to an HTML parser to crawl the content.
!pip install asyncpraw
!pip install --upgrade telethon
!pip install telethon nest_asyncio
import asyncio
import asyncpraw
import nest_asyncio
import pandas as pd
import random
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from telethon import TelegramClient
from telethon.errors import PhoneCodeInvalidError, SessionPasswordNeededError
from telethon.tl.functions.messages import GetHistoryRequest
from telethon.tl.types import PeerChannel
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import re
# Download NLTK data files
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
# Initialize stopwords and lemmatizer
stop_words = set(stopwords.words('english'))
lemmatizer = nltk.WordNetLemmatizer()
# Define a pattern to remove emojis and special characters
emoji_pattern = re.compile(
"["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002500-\U00002BEF" # Chinese characters
u"\U00002702-\U000027B0" # Dingbats
u"\U0001F926-\U0001F937"
u"\U00010000-\U0010ffff"
u"\u2640-\u2642"
u"\u2600-\u2B55"
u"\u200d"
u"\u23cf"
u"\u23e9"
u"\u231a"
u"\ufe0f" # Dingbats
u"\u3030"
"]+", flags=re.UNICODE
)
def is_relevant(text):
# Define patterns to identify non-relevant data
ad_patterns = [
r'http\S+', # URLs
r'www\S+',
r'https\S+',
r'join our telegram',
r'follow us on',
r'click here',
r'visit our website',
r'\b(buy|sell)\b', # common advertising keywords
r'\b(bot|automated)\b' # bot-related keywords
]
# Check for institutional or bot-like comments
if any(re.search(pattern, text, re.IGNORECASE) for pattern in ad_patterns):
return False
return True
def preprocess_text(text):
if not is_relevant(text):
return None # Skip non-relevant data
# Remove emoji
text = emoji_pattern.sub(r'', text)
# Remove URLs and non-alphabetical characters
text = re.sub(r'http\S+|www\S+|https\S+|\@\w+|[^a-zA-Z\s]', '', text, flags=re.MULTILINE)
# Lowercase the text
text = text.lower()
# Tokenize the text
word_tokens = word_tokenize(text)
# Remove stopwords
filtered_text = [word for word in word_tokens if word not in stop_words]
# Lemmatize the text
lemmatized_text = [lemmatizer.lemmatize(word) for word in filtered_text]
return ' '.join(lemmatized_text)
def preprocess_dataset(dataset):
return [preprocess_text(text) for text in dataset if preprocess_text(text) is not None]
# Reddit Data Collection
CLIENT_ID = '82dtnfocqa02q3prkbwVJg'
CLIENT_SECRET = '1cZbtlW_TIza_ehhaYZAqj0-W6oLbg'
USERNAME = 'USERNAME'
PASSWORD = 'PASSWORD'
USER_AGENT = 'USERAGENT'
async def fetch_reddit_posts(subreddit_name, limit=500):
reddit = asyncpraw.Reddit(
client_id=CLIENT_ID,
client_secret=CLIENT_SECRET,
username=USERNAME,
password=PASSWORD,
user_agent=USER_AGENT
)
posts = []
subreddit = await reddit.subreddit(subreddit_name)
async for post in subreddit.hot(limit=limit):
posts.append({'title': post.title, 'created': post.created_utc})
await reddit.close()
return posts
# BitcoinTalk Data Collection
def fetch_bitcointalk_posts(thread_url, num_pages=6):
posts = []
for page in range(num_pages):
url = f"{thread_url}.{page * 20}" # BitcoinTalk pagination: add page offset
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for post in soup.find_all('div', class_='post'):
post_content = post.get_text(separator=" ", strip=True)
# Try to find the post date
post_date_element = post.find('div', class_='smalltext')
if post_date_element:
post_date = post_date_element.text
else:
# Handle the case where the date is not found
post_date = 'Unknown'
posts.append({'content': post_content, 'created': post_date})
return posts
# Apply the nest_asyncio patch
nest_asyncio.apply()
api_id = 'YOUR API ID'
api_hash = 'YOUR API'
phone_number = 'YOUR NUMBER'
# Initialize the client
client = TelegramClient('session_name', api_id, api_hash)
async def fetch_telegram_messages(channel_username, limit=500):
print("Connecting to Telegram...")
await client.connect()
if not await client.is_user_authorized():
print("Sending code request...")
await client.send_code_request(phone_number)
code = input('Enter the code you received: ')
try:
await client.sign_in(phone_number, code)
except PhoneCodeInvalidError:
print("Invalid code entered. Please try again.")
return []
except SessionPasswordNeededError:
password = input('Two-step verification enabled. Please enter your password: ')
await client.sign_in(password=password)
try:
print(f"Fetching messages from {channel_username}...")
channel = await client.get_entity(channel_username)
history = await client(GetHistoryRequest(
peer=channel,
limit=limit,
offset_date=None,
offset_id=0,
max_id=0,
min_id=0,
add_offset=0,
hash=0
))
messages = [{'message': message.message, 'created': message.date} for message in history.messages if message.message]
return messages
except Exception as e:
print(f"An error occurred: {e}")
return []
finally:
await client.disconnect()
# Main Function to Collect and Preprocess Data
async def main():
# Reddit
subreddits = ['CryptoCurrency', 'Bitcoin', 'CryptoMoonShots', 'Ethereum', 'SHIBArmy', 'algotrading']
reddit_tasks = [fetch_reddit_posts(sub, limit=50) for sub in subreddits]
all_reddit_posts = await asyncio.gather(*reddit_tasks)
reddit_data = []
for sub, posts in zip(subreddits, all_reddit_posts):
for post in posts:
reddit_data.append({'Message': post['title'], 'Source': 'Reddit', 'Created': datetime.utcfromtimestamp(post['created']).isoformat()})
# BitcoinTalk
thread_urls = [
'https://bitcointalk.org/index.php?topic=5490782.0',
]
bitcoin_data = []
for url in thread_urls:
posts = fetch_bitcointalk_posts(url, num_pages=1)
for post in posts:
bitcoin_data.append({'Message': post['content'], 'Source': 'BitcoinTalk', 'Created': post['created']})
# Telegram
channel_usernames = ['CRYPTO_jokker', 'CRYPTO_insidderr', 'blumcrypto', 'Crytpo_Woolf', 'bittonapp', 'blumcrypto', 'whalepumpgroup', 'cryptobull']
telegram_data = []
for username in channel_usernames:
messages = await fetch_telegram_messages(username, limit=50000)
for message in messages:
telegram_data.append({'Message': message['message'], 'Source': 'Telegram', 'Created': message['created'].isoformat()})
# Combine all data
all_data = reddit_data + bitcoin_data + telegram_data
# Preprocess the combined data
preprocessed_messages = preprocess_dataset([data['Message'] for data in all_data])
# Combine preprocessed data with metadata
combined_data = []
current_date = datetime.now().isoformat()
for data, preprocessed_message in zip(all_data, preprocessed_messages):
if preprocessed_message:
combined_data.append({
'Message': preprocessed_message,
'Source': data['Source'],
'Date_Crawled': current_date,
'Date_Created': data['Created']
})
# Create a DataFrame from the combined data
df = pd.DataFrame(combined_data)
# Add an empty column for sentiment labels
df['Sentiment'] = ''
# Save the DataFrame to a CSV file
df.to_csv('evv.csv', index=False)
print(df)
print("Sampled data saved to 'sampled_data_for_annotation.csv' for manual annotation.")
# Run the main function and get the preprocessed data
preprocessed_data = asyncio.run(main())
Data Processing Techniques
The code provided for crawling social media data also has several data processing techniques such as:
1. Stopword Removal
Stop words such as “and,” “the,” “is,” etc. are removed from the crawled data. This allows the data to have more meaningful words. On the other hand, the stopwords set from the NLTK library is used for this purpose.
2. Lemmatization
Lemmatization is used to break the words into their base form while considering the word’s context. For example, “running” is converted to “run.” The NLTK WordNetLemmatizer is employed to perform this task.
3. Emoji Removal
A pattern is defined to remove emojis and special characters from the text since they may not convey the true meaning behind the sentiment. I used a regular expression that targets various Unicode ranges corresponding to emojis and special symbols
4. URLs and Non-Alphabetical Characters Removal
A regular expression pattern is also used to remove irrelevant data such as URLs, ad-related data, and bot-generated content. Based on the code, the pattern includes:
‘r’http\S+’ (to remove URLs)
‘r’www\S+’
‘r’https\S+’
‘r’join our telegram’
‘r’follow us on’
‘r’click here’
‘r’visit our website’
‘r’\b(buy|sell)\b’ (to remove common advertising keywords)
‘r’\b(bot|automated)\b’ (to remove bot-related keywords)
5. Handling Institutional Comments
The regular expression pattern is also used in a function to ensure the data only includes individual investor sentiments. This is because institutional investors such as hedge funds, banks, etc. have large portfolios that can cause swift market movements.
But while institutional investors have large portfolios, they are fewer compared to daily traders and spectators. Thus, based on the purpose of your analysis, it might be better to focus on individual investors since they are more and these sentiments would be more representative of what the majority of the market thinks.
Data Augmentation for Social Media Sentiment
Ideally, you should either ues the same data instances from each platform, or determine the ratio based on how relevant a platform is impactful in your analyis. For instance, you may want a greater percentage of data from Telegram if you’re building a predictive model for scalping while more data from Reddit and BitcoinTalk may be more ideal for medium term and long term analysis.
In each case if you have an underepresented class, which might cause your model not to learn well for certain class labels, you could consider creating synthetic data for this class. Here, augmentation can be used to create new data instances using the structure of the old data. Synonyms may be used for the new data instances.
Here’s a code that’ll help you get started with the augmentation process:
import pandas as pd
input_csv = 'REPLACE WITH YOUR FILES'S LOCATION'
df = pd.read_csv(input_csv)
# Split the dataframe based on the 'source' column
reddit_df = df[df['Source'] == 'Reddit']
bitcointalk_df = df[df['Source'] == 'BitcoinTalk']
telegram_df = df[df['Source'] == 'Telegram']
# Save the resulting dataframes to separate CSV files
reddit_csv = 'reddit.csv'
bitcointalk_csv = 'bitcointalk.csv'
telegram_csv = 'telegram.csv'
reddit_df.to_csv(reddit_csv, index=False)
bitcointalk_df.to_csv(bitcointalk_csv, index=False)
telegram_df.to_csv(telegram_csv, index=False)
print(f"Files have been saved as {reddit_csv}, {bitcointalk_csv}, and {telegram_csv}")
Machine Learning Techniques for Crypto Data
There are several machine learning techinques you can use to predict crypto price using the current dataset you have.
These techniques include:
- Logistic regression
- Random Forest Classifier
- Support Vector Machine
Logistic Regression
This is a simple modeling technique you can use to classify the sentiment you get from social media pages.
Given that this is a classiifcation task where sentiments are in classes such as positive, negative, neutral, very positive, and very negative, it might help.
Ideally, logistic regression is used for binary classification but it can also be used for multiclass classiifcation. Hence, if you need a simple place to start from, you might choose this approach.
The next step would be to encode the labels into numbers before correlating with the price data you crawled.
Ethical Review Considerations
Ethical review is important if you’re crawling social media data. This will ensure you adhere data privacy and security standards while handling comments from these platforms. Some considerations would include:
1. Data Storage
You’d have to store the sentiment data in a safe medium. It could be an online or offline resource. You may also have to delete the data using it for its intended purpose.
2. Data Privacy
The details of such crawled data will not be a part of your publications, hence, discuss only the results of the analysis.
Combine Sentiment Scores with Market Data
Asides building predictive model, you may want to carry out correlation analysis between the Bitcoin price data and social media data. The first step to begin is averaging sentiment scores.
Averaging Sentiment Scores
Sentiment scores can be calculated by averaging the sentiments of all messages for a particular date, a positive score (+1) and a negative score (-1) on the same date would result in an average score of 0.
For example:
- Positive Sentiment: +1
- Negative Sentiment: -1
Average: (+1 + (-1)) / 2 = 0
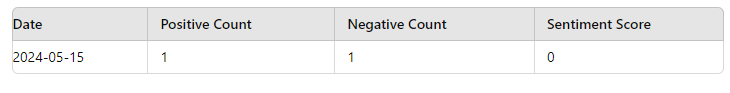
You can then combine the calculated sentiment scores with the market data (price, volume, etc.) from Cryptocompare to form one dataset as shown in Figure 3.
However, I needed to filter out the price data to ensure its date corresponds with those available in the new sentiment data. This filtering is shown in Figure 4 .
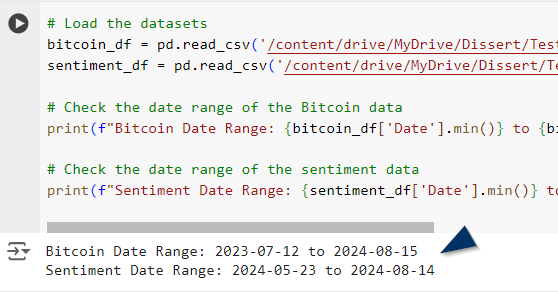
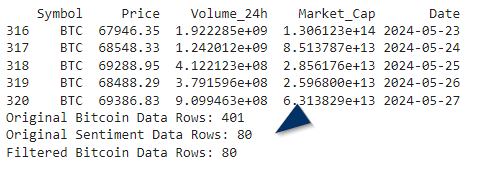
Correlation Analysis
You can perform time-series analysis to correlate sentiment scores with market prices.
Two initial correlation analyses can performed. These are:
- A correlation with the sentiment scores and Bitcoin only.
- A correlation with sentiment scores and average price of the 10 selected cryptocurrencies to understand the overall market sentiment.
Pearson correlation can be used to calculate the correlation between social media sentiment and crypto price. The result may show a weak linear relationship between social media sentiment and market prices.
This correlation can be checked with different sizes of datasets. In my findings, I discovered that the correlation was weaker with smaller datasets and a bit stronger with more datasets.
For instance, the correlation was around 0.0004 when 500 data instances were used covering 30 days. However, the correlation score was closer to 0.0012 when the data set was increased to 2000 spanning across 3 months.
Conclusion
You now know how to get the Bitcoin price dataset as well as that for other cryptocurrencies. These steps would also help you get started with crawling social media data for related projects. Encountered issues? Let me know in the comment section.